单一头文件
对将一个程序划分成几个文件的最简单解决方案就是将所有定义放入合适数目的 .c 文件里,在一个头文件里声明这些 .c 文件之间通信所需要的类型,并让它们中的每个都#include该头文件。对于计算器程序而言,我们可以用5个 .c 文件 --- lexer.c、parser.c、table.c、error.c和main.c,用它们保存所有的函数和数据定义;再加上一个 dc.h,其中存储在不止一个 .c 文件里使用的所有名字和声明。
头文件 dc.h 看起来大致是下面的样子:
// dc.h:
namespace Error {
struct Zero_divide {};
struct Syntax_error {
const char* p;
Syntax_error (const char* q) { p = q; }
};
}
#include <string>
namespace Lexer {
enum Token_value {
NAME, NUMBER, END,
PLUS='+', MINUS='-', MUL='*', DIV='/',
PRINT=';', ASSIGN='=', LP='(',, RP=')'
};
extern Token_value curr_tok;
extern double number_value;
extern std::string string_value;
Token_value get_token();
}
namespace Parser {
double prim(bool get); // 处理初等项
double term(bool get); // 乘和除
double expr(bool get); // 加和减
using Lexer::get_token;
using Lexer::curr_tok;
}
#include <map>
extern std::map<std::string, double> table;
namespace Driver {
extern int no_of_errors;
extern std::istream* input;
void skip();
}
将关键字extern用在每个变量声明上,可以保证当我们用#include将 "dc.h" 包含到各个 .c 文件后,不会出现重复定义的情况。对应的定义可以在适当的 .c 文件中找到。
把实际代码放到一边,lexer.c大致是下面的样子
// lexer.c
#include "dc.h"
#include <iostream>
#include <cctype>
Lexer::Token_value Lexer::curr_tok;
double Lexer::number_value;
std::string Lexer::string_value;
Lexer::Token_value Lexer::get_token() { /* ... */ }
以这种方式使用头文件,就能保证在头文件中的每个声明都将在某个地方被包含到它的定义所在的文件里。例如,在编译lexer.c时,提交给编译器的将是
namespace Lexer { // 来自dc.h
// ...
Token_value get_token();
}
// ...
Lexer::Token_value Lexer::get_token(){ /* ... */ }
这就保证了编译器能够查出一个名字的类型描述之间不一致的情况。例如,假设get_token()被声明为返回Token_value,而定义为返回int,对lexer.c的编译将因为遇到了类型不匹配的错误而失败。如果缺少某个定义,连接器将捕捉到这个错误。如果缺少某个声明,就会有某个 .c 文件无法编译。
文件parser.c看起来像下面这样:
// parser.c:
#include "dc.h"
double Parser::prim(bool get) { /* ... */ }
double Parser::term(bool get) { /* ... */ }
double Parser::expr(bool get) { /* ... */ }
文件table.c看起来像下面这样:
// table.c:
#include "dc.h"
std::map<std::string, double> table;
符号表就是标准库map类型的一个变量,这里把table定义成了全局变量。在实际规模的程序里,这类对于全局名字空间的小污染也会累积起来,最终造成严重问题。我在这里留下一个瑕疵,就是为了能有机会提出对此问题的警告。
最后,main.c将具有下面的样子
// main.c
#include "dc.h"
#include <sstream>
int Driver::no_of_errors = 0;
std::istream* Driver::input = 0;
void Driver::skip() { /* ... */ }
int main(int argc, char* argv[]){ /* ... */ }
为能被当做整个程序的main(),必须将main()声明为全局函数,所以这里没用名字空间。
整个系统的物理结构可以用下面图形表示:
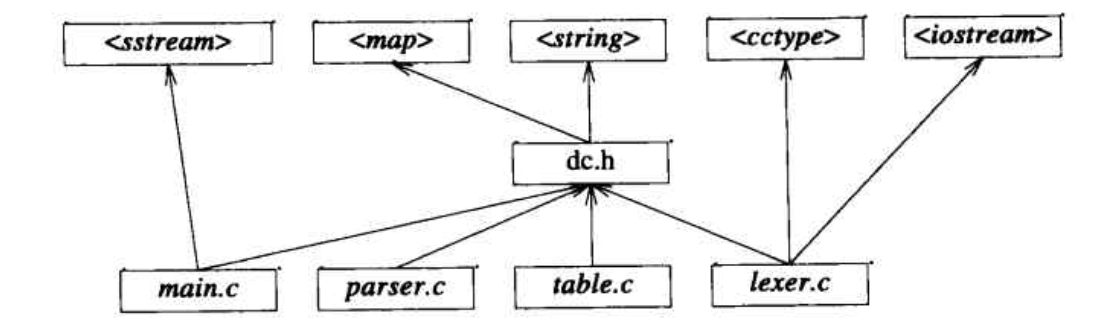
请注意,位于最上面的头文件都是标准库提供的头文件。对于许多程序分析形式而言,这些库都可以忽略不管,因为它们是众所周知的、稳定的。对于很小的程序,这种结构还可以简化,只要将所有的#include指令都移到那个公共的头文件里。
当程序很小,而且其中各个部分都不打算分开使用时,采用这种单一头文件风格的物理划分就很合适。请注意,因为这里使用了名字空间,在dc.h里仍然表现出程序的逻辑结构。如果不使用名字空间,结构就会模糊了,虽然写一些注释可能会有所帮助。
对于更大的程序,在常规的基于文件的开发环境中,单一头文件方式就无法工作了。因为,对公共头文件的修改就将导致对整个程序的重新编译,几个程序员去修改一个头文件也极容易造成错误。除非我们进一步把强调的重点放到依靠名字空间和类的程序设计风格上,否则,随着程序的增大,其逻辑结构的品质就会逐渐恶化。
🔚